概要
トピックモデルとは, 文書集合から特徴(話題)を抽出する手法です. また, それぞれの文書が持つ話題を抽出したり, 文書間の類似性を抽出することが可能な手法です.
そこで今回は, トピックモデルを用いてニュース記事を対象に話題を抽出する実験を行ってみます. なお, トピックモデルの中でも特に潜在意味解析(latent semantic analysis, LSA)を実際に用いています(正確には, LSAはベクトル空間モデルであり, このLSAを確率モデルに拡張した確率的潜在意味解析がトピックモデルです. しかし, トピックモデルのカテゴリ(離散値確率)分布は, LSAで用いる行列分解手法として捉えることができるので, 僕は同じ物として扱っています).
潜在意味解析(latent semantic analysis, LSA)
LSAは, 文書集合データを(文書総数 x 単語数)の行列Nで表現したときに, 掛け合わせることで再び元の行列を構築できるような, 小さな(低ランクの)2つの行列を見つけることをします(これを非負値行列因子分解と言います). このとき, それぞれの行列は特徴の組み合わせで構築されているため, この特徴を用いることによって文書に潜在するトピック(文書を特徴づける単語)を抽出します.
非負値行列因子分解(nonnegative matrix factorization, NMF)
NMFとは, 行列で表現した文字・画像・音声などのデータ(非負値行列)を指定する基底数に行列分解し, 低ランクの表現にすることによって, それぞれの行列が持つ潜在的な特徴を抽出することを可能にした行列低ランク近似手法です. 簡単に言えば, 非負値行列を2つの非負値行列に分解するアルゴリズムです. 以下, NMFについて詳細に説明します.
図1に示すように, 文書集合データを(D x V)の行列Nで表現するとします. ここでDは文書総数, Vは単語数です.
このNを分解すると, W(K x D)の基底行列とH(K x V)の特徴重みの行列となります. そしてこれらWとHを掛け合わせることにより, 元の行列Nの近似値が得られますが, 完全に一致する行列W, Hの値を求めるのは困難です.
そこで, この近似値を求める問題は, 行列Nと転置したWにHを掛け合わせた行列の距離を小さくする問題として扱うことができます. 具体的には, フロベニウスノルムの最小化を行います(図2).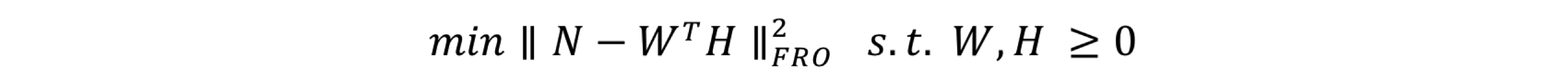
フロベニウスノルムの最小化問題には, 模擬アニーリングや勾配降下法, 乗法的更新ルールなど, いくつかの数学的解法が提案されていますが, NMFで最も用いられる解法は乗法的更新ルールです(参考論文).
乗法的更新ルールの式を図3に示します.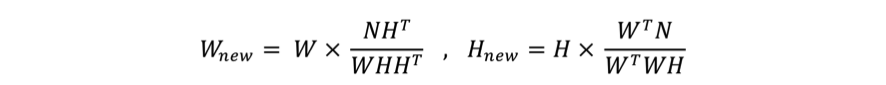
そして, フロベニウスノルムの最小化問題を解くために, NMFでは行列WとHをランダムな値で初期化し, 乗法的更新ルールの式にしたがってWとHを更新して距離が収束するまでこの処理を繰り返します. NMFはこのようにして行列の低ランク近似を行います.
方針
- ニュース記事を文書として, 大量の文書から話題になっているトピックを抽出します. さらに, 話題になっているトピックを持つ文書を抽出します.
- 各文書が持つ潜在的な話題を抽出します.
方法
- 様々な分野の情報を発信するサイトAll Aboutが公開しているRSSを用いて文書を収集する.
- 収集した各文書について本文抽出, 形態素解析の処理を施すことによって形態素単位で分かち書きする.
- 単語をBOW(bug-of-words)表現する.
- 各文書に存在する単語について, その文書における出現回数を数える.
- 全文書に存在する単語について, 全文書における出現回数を数える.
- 1と2から特徴行列と特徴単語の集合を生成する.
- NMFを用いて文書の持つ潜在的な特徴を抽出する.
実装
BOWの実装
- Pythonのfeedparserを用いてRSSから文書を取得します. この時, 出来るだけ異なる分野の記事(RSS)を取得するようにします. これはトピックモデル全般に言えることです. 今回は下記のRSSを使用しました.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17feedlist=['http://rss.allabout.co.jp/aa/latest/ch/health/',
'http://rss.allabout.co.jp/aa/latest/ch/house/',
'http://rss.allabout.co.jp/aa/latest/ch/domestic/',
'http://rss.allabout.co.jp/aa/latest/ch/ch_creditcard/',
'http://rss.allabout.co.jp/aa/latest/ch/beautydiet/',
'http://rss.allabout.co.jp/aa/latest/ch/mobile/',
'http://rss.allabout.co.jp/aa/latest/ch/pet/',
'http://rss.allabout.co.jp/aa/latest/ch/marriage/',
'http://rss.allabout.co.jp/aa/latest/ch/mensbeauty/',
'http://rss.allabout.co.jp/aa/latest/ch/fashion/',
'http://rss.allabout.co.jp/aa/latest/ch/ch_sweets/',
'http://rss.allabout.co.jp/aa/latest/ch/examination/',
'http://rss.allabout.co.jp/aa/latest/ch/auto/',
'http://rss.allabout.co.jp/aa/latest/ch/homeelectronics/',
'http://rss.allabout.co.jp/aa/latest/ch/ch_sports/',
'http://rss.allabout.co.jp/aa/latest/ch/ch_game/',
'http://rss.allabout.co.jp/aa/latest/ch/ch_hobby/'] - 取得したHTMLから本文の抽出を行います. 具体的には, HTMLタグを除いた文字列を集める処理を施します.
1
2
3
4
5
6
7
8
9
10def stripHTML(h):
p=''
s=0
for c in h:
if c=='<': s=1
elif c=='>':
s=0
p+=' '
elif s==0: p+=c
return p - 抽出した本文を形態素単位で分かち書きします. 具体的には, 形態素解析器Janomeを用いて形態素解析し, 定める単語単位で分かち書きします. 定める単語は, 以下のルールに従う単語としました.
- 名詞であること
- 接尾辞でないこと
- 代名詞でないこと
- 非自立語でないこと
- 数でないこと
- 形容動詞語幹でないこと
- (英単語の場合)文字列長が4以上であること
下記, 単語を分割するコード.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def separatewords(text):
separatedWord=[]
t=Tokenizer()
tokens=t.tokenize(unicode(text, "utf-8"))
for token in tokens:
posList=token.part_of_speech.split(",")
pos1=posList[0]
if isinstance(pos1, unicode):
pos1=pos1.encode("utf-8")
pos2=posList[1]
if isinstance(pos2, unicode):
pos2=pos2.encode("utf-8")
ruby=token.reading
if isinstance(ruby, unicode):
ruby=ruby.encode("utf-8")
if pos1=="名詞":
if pos2!="接尾" and pos2!="代名詞" and pos2!="非自立" and pos2!="数" and pos2!="形容動詞語幹":
if ruby!="*":
separatedWord.append(token.surface.lower())
print token.surface.lower()
elif pos2!="サ変接続" and len(token.surface)>3:
# 英単語に関しては4文字以上の単語を扱う
separatedWord.append(token.surface.lower())
print token.surface.lower()
return separatedWord
- 単語をBOW表現します. 具体的にはRSSで取得した文書について, タイトルと本文を抽出して存在する単語の数をカウントします. そして, 単語の出現回数を保持した行列を生成します.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30def getarticlewords():
allwords={} # 全文書の総単語とその出現回数
articlewords=[] # 各文書の総単語とその出現回数
articletitles=[] # 文書タイトル
ec=0
for feed in feedlist:
f=feedparser.parse(feed)
# すべての記事をループする
for e in f.entries:
# 同一の記事の場合は飛ばす
if e.title in articletitles: continue
# 単語を抽出する
txt=e.title.encode('utf8')+stripHTML(e.description.encode('utf8'))
words=separatewords(txt)
articlewords.append({})
articletitles.append(e.title)
# allwordsとarticlewordsにあるこの単語のカウントを増やす
for word in words:
allwords.setdefault(word,0)
=1
articlewords[ec].setdefault(word,0)
=1
=1
return allwords,articlewords,articletitles - 行を文書総数, 列を特徴単語総数とした特徴行列と, 全文書に存在する特徴単語の集合を生成します. なお, 特徴単語は一般的な単語であるが一般的すぎない単語としました. 具体的には, 1文書に出現する回数が4以上, かつ文書総数の6割未満の単語を特徴単語としました.
1
2
3
4
5
6
7
8
9
10
11def makematrix(allw,articlew):
wordvec=[]
# 一般的だが一般的すぎない(特徴があるとする)単語のみを利用する
for w,c in allw.items():
if c>3 and c<len(articlew)*0.6:
wordvec.append(w)
# 各文書における特徴単語の出現回数の分布を持つ行列(特徴行列)を生成する
l1=[[(word in f and f[word] or 0) for word in wordvec] for f in articlew]
return l1,wordvec - Pythonインタプリタを使い, 上記コードによって取得した文書から特徴単語を抽出し, BOW表現する様子を確認してみたいと思います. なお, 上記コードをまとめたファイルをGitHubにあげておきます. 取得した記事340個から特徴単語を513個抽出できました. そしてBOW表現した特徴行列wordmatrixが得られました.
1
2
3
4
5
6
7
8
9
10
11
12$ python
> import newsfeatures
> allw,artw,artt=newsfeatures.getarticlewords()
> wordmatrix,wordvec=newsfeatures.makematrix(allw,artw)
> len(artt)
340
> len(wordvec)
513
> len(wordmatrix)
340
> len(wordmatrix[0])
513
NMFの実装
特徴行列が得られたので, NMFによって文書の持つ潜在的な特徴を抽出します.
- フロベニウスノルムの最小化のために, 残差平方和を求めるプログラムを用意します.
1
2
3
4
5
6
7def difcost(a,b):
dif=0
for i in range(shape(a)[0]): # 行
for j in range(shape(a)[1]): # 列
dif+=pow(a[i,j]-b[i,j],2)
return dif - NMFを実装します. 引数にはNMFする(numpyでmatrix化した)特徴行列, 因子の数, 乗法的更新ルールで更新する回数を与えます. なお, ここで与える因子の数が全文書から抽出したいトピックの数になります.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32def factorize(v,pc=10,iter=50):
ic=shape(v)[0] # vの行数
fc=shape(v)[1] # vの列数
# 重みの行列(w)と特徴の行列(h)をランダムな値で初期化
w=matrix([[random.random() for j in range(pc)] for i in range(ic)])
h=matrix([[random.random() for i in range(fc)] for i in range(pc)])
# 乗法的更新ルール. iter回繰り返す
for i in range(iter):
wh=w*h
# 残差平方和の計算
cost=difcost(v,wh)
# 10回ごとに残差平方和を表示
if i%10==0: print cost
# 行列が完全に因子分解されたら終了
if cost==0: break
# 特徴重みの行列を更新
hn=(transpose(w)*v)
hd=(transpose(w)*w*h)
h=matrix(array(h)*array(hn)/array(hd))
# 基底行列を更新
wn=(v*transpose(h))
wd=(w*h*transpose(h))
## 実行時にエラー(RuntimeWarning: invalid value encountered in divide)が出るなら
#wd = [[1e-20 if (x - 1e-20 < 0) else x for x in lst] for lst in wd.tolist()]
w=matrix(array(w)*array(wn)/array(wd))
return w,h - 上記コードによって生成されるのは基底行列と特徴重みの行列なので, 抽出したトピックを見やすい形式で表示する&ファイルに書き出すプログラムを用意します.
このプログラムにより, 抽出したトピック(トピックにおいて出現確率が高い特徴単語6個)と, そのトピックを持つ文書上位3件を表示&書き出します.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44def showfeatures(w,h,titles,wordvec,out='features.txt'):
with open(out, "w") as outfile:
pc,wc=shape(h)
toppatterns=[[] for i in range(len(titles))]
patternnames=[]
# 因子数分繰り返し
for i in range(pc):
slist=[]
# 単語とその重みのリストを作る
for j in range(wc):
slist.append((h[i,j],wordvec[j]))
# 単語のリストを降順に並び替え
slist.sort()
slist.reverse()
# 上位6つの要素(特徴語)を出力
n=[s[1] for s in slist[0:6]]
outfile.write(str(n)+'\n')
print "トピック" + str(i+1) + ": ",
for hoge in n:
print hoge,
print ""
patternnames.append(n)
# 当該特徴を持つ文書のリストを作る
flist=[]
for j in range(len(titles)):
# 該当する重みに対応する文書タイトルを重みに結合
flist.append((w[j,i],titles[j]))
toppatterns[j].append((w[j,i],i,titles[j]))
flist.sort()
flist.reverse()
# 上位3つの文書を表示
for f in flist[0:3]:
outfile.write(str(f)+'\n')
for hoge in f:
print hoge,
print ""
outfile.write('\n')
return toppatterns,patternnames - 実際に, 特徴行列にNMFを適用して得られるトピックを確認してみます. なお, 因子数を20個, イテレーション数を50回としました. 指定した因子数20個分のトピックと, それを最も表現する特徴単語(そのトピックにおいて出現確率が高い単語 = 共起する単語), およびそのトピックを持つ文書を1トピックにつき上位3件表示しました. なお, プログラムと同階層に結果を書き出したファイルfeatures.txtが生成されます.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89>>> import nmf
>>> v=matrix(wordmatrix)
>>> weights,feat=nmf.factorize(v,pc=20,iter=50)
4644026.99428
6276.23883311
6106.81822625
6076.58094169
6064.71184922
>>> topp,pn=nmf.showfeatures(weights,feat,artt,wordvec)
トピック1: メーカー 特徴 家 大手 マリオ 住宅
15.4663497597 ヒーターのメーカー別の特徴
13.3104830612 ゲーム業界から見たスーパーマリオメーカー問題
13.2819191304 似て非なる大手住宅メーカー10社の特徴まとめ【2016年版】
トピック2: ポイント 楽天 現金 方法 ネット スーパー
19.7595240853 無印良品で楽天スーパーポイントやTポイントを貯める
16.7933330305 ポイント交換手数料がかからずに現金化する方法とは?
13.6775064617 Amazonの買い物で2つのポイントを貯める!
トピック3: カード ドコモ 利用 クレジットカード サービス メイン
22.0895104043 dポイントカードは持っていたほうが良い?
17.0282753695 クレジットカード、2枚目はこうやって選べ!
14.0005808073 まだまだあるdカード・dカード GOLDの魅力とは?
トピック4: 人 口内 口 トラブル 環境 悪化
23.2705036456 口臭や口内炎、原因は口内環境の悪化?ケアして解消
20.316718056 全身の健康は口から 口臭を「クマ笹歯みがき」で予防
6.55166834564 頭皮のかゆみ…くりかえす原因は常在菌による炎症?
トピック5: 紹介 方法 iphone 機能 今回 ダイエット
11.9575251978 iPhoneで着信時に通知ランプを点滅させる方法
10.3358206124 機能豊富なiPhoneのカメラアプリを使いこなそう
10.1530091745 iPhone標準ブラウザ「Safari」の便利機能10選
トピック6: 対策 指輪 雪 女性 試験 男性
15.9903054461 都心で雪が降る日に慌てないようやっておくべき全対策
12.2442409343 既婚者なのに結婚指輪をつけない男性のホンネと対策
8.33584814286 便秘太りさん必見、原因別の「腸活」便秘対策法
トピック7: 将棋 愛 ガイド 登場 宴会 シーン
19.9652514536 将棋ファン感涙!将棋シーンが登場する漫画10選
14.6345881045 愛棋家ぶらり旅ガイド(1)別府・将棋処「と」
14.2962735508 愛棋家のための宴会ソング-将棋替え歌・キュート編
トピック8: 子ども 薬 親 問題 ストレス 受験
19.6893953432 子どもの将来を受験で潰さないために…親の心得と接し方
17.960475885 アイスやジュースはNG!薬を嫌がる子供への飲ませ方
15.0014403268 子どもを薬嫌いにさせないための「服薬補助ゼリー」
トピック9: ヨガ ポーズ 人 犬 効果 下
24.9219551555 基本のヨガポーズをマスター!下を向いた犬のポーズ
15.0087767171 まずはココから!自宅でできる初心者向けのヨガポーズ
11.0473594218 初心者でも簡単!?「空中ヨガ」で新感覚エクササイズ
トピック10: 体 幹 トレーニング メニュー 基本 効果
34.4317754799 体幹トレーニングの基本5メニューで、劇的に体型を変える!
14.7631212143 冬太り撃退に!体幹トレーニング「レッグバランス」
13.7327354842 【動画】1分で簡単!効果絶大な体幹トレーニング3選
トピック11: 人気 パン カフェ コーヒー 栃木 中古
13.7362428489 栃木を訪れたら絶対食べたい! 地元で愛される人気パン6選
12.6581465276 【中古車】ルパンにも登場した人気の名車6選【自動車】
10.5455508799 人気のフィアット500が新車時の半額以下に!
トピック12: 紹介 今回 日本 月 金沢 五輪
11.911419134 ルーペで味わい尽くす!凹版切手の魅力
11.4798284003 贈って喜ばれる!金沢っ子おすすめの新おいしいお土産
11.0113306297 これぞ日本の美!奥の細道シリーズの魅力に迫る!
トピック13: チョコ バレンタイン 褒美 自分 ショコラ チョコレート
22.566436019 スリーエフのバレンタイン2016!ご褒美チョコ&感謝チョコ厳選5
19.0753834192 ファミマのバレンタイン2016!あの人気店の味&本格チョコ厳選7
17.9912005562 自分へのご褒美チョコレート2016厳選バレンタイン
トピック14: プレート ホット 鍋 グリル 方式 選び方
19.1341121925 ホットプレートとグリル鍋の違い
18.6032897757 ホットプレート・グリル鍋のメーカー別特徴
14.5889482845 ホットプレート・グリル鍋の加熱方式
トピック15: 木 魅力 街 プロ 紹介 場所
37.0109893407 街に暮らしにもっと木を!木のプロが語る「木化」とは
4.33374555819 自然豊かな表情が魅力の「国産ナラ材」
2.98959349923 プロは楽して踊っていると言う事実
トピック16: 住宅 建築 設計 事務所 経験 現在
21.6811595627 納谷学+納谷新[納谷建築設計事務所]
16.2771733003 岸本和彦[acaa建築研究所]
14.5906325228 ヴィンテージ住宅のリノベーション[井の頭の住宅]
トピック17: 猫 目 映画 今回 理由 妊娠
19.7927332553 猫の目を見つめてはダメ?
18.6993266635 猫が帰って来ない!?迷い猫の探し方
16.6343533117 立つ猫――猫が二本足になる理由って?
トピック18: 塾 選び 受験 チェックポイント 中学生 失敗
24.2675675159 塾選び、個別指導塾の盲点とチェックポイント
21.8312760412 失敗しない塾選び、7つのポイント
14.4755082856 意外な盲点に注意!中学生の塾選びのポイント
トピック19: 冬 雪見 露天風呂 温泉 紹介 季節
23.088694487 冬の温泉旅におすすめ!関東周辺の雪見露天風呂10選
17.645473759 脱・冬太り!スッキリボディを手に入れる冬太りストップダイエット
13.3875534695 美肌効果も期待大! 東京から行ける雪見露天5選
トピック20: トレンド 春 夏 ファッション 厳選 キーワード
16.0910792269 2016春夏トレンド5「ランジェリーエッセンス」
14.6996582741 2016春夏トレンド6「モダンオールディーズ」
14.5019972252 2016春夏トレンド4「リーンエフォートレス」
結果を見ると, それぞれのトピック(各トピックにおいて出現確率が最も高い単語)ごとに関連した単語が抽出できていることが確認できます. 特にトピック13の「チョコ」なんかは, 「バレンタイン 褒美 自分 ショコラ チョコレート」のように, チョコととても関係の深い単語が抽出できていることがわかります.
さらに, そのトピックを持つ上位3件の文書を実際に確認したところ, トピック13のチョコにおいては, 「スリーエフのバレンタイン2016!ご褒美チョコ&感謝チョコ厳選5 」「ファミマのバレンタイン2016!あの人気店の味&本格チョコ厳選7 」「自分へのご褒美チョコレート2016厳選バレンタイン」の全てが, まさにチョコな記事でした.
最後に, 各文書が持つ潜在的なトピックを確認します. 下記コードでは, 各文書に潜在するトピックの上位3つを表示するとともに, 結果をファイルに書き出します.
1 | def showarticles(titles,toppatterns,patternnames,out='article.txt'): |
それでは実行してみます.
1 | >>> nmf.showarticles(artt,topp,pn) |
全文書(340記事)について, 各文書の持つ潜在的なトピック上位3つを表示しました. なお, プログラムと同階層に結果を書き出したファイルarticle.txtが生成されます.
実際に, 340個目の文書「東京から日帰りで行ける、無料でも十分に楽しめる見学施設」を確認したところ, 抽出されたトピック通り, 「冬」に行って楽しめる「人気」の施設を「紹介」している記事でした. トピックをうまく抽出できているようです. 文書の持つ話題を的確に捉えていることが確認できました.
それではNMFの実装コードをまとめたファイルもGitHubにあげておきます.
まとめ
本記事ではトピックモデルの一種であるLSAを用いることによって, 多くのニュース記事から話題になっているトピックを抽出しました. また, 各文書が持つ潜在的な話題の抽出も行いました.
結果より, 文書が持つ話題を的確に抽出していることが確認できましたが, 「紹介」というトピックや, トピックにおいて出現確率の高い単語として「今回」「現在」のような副詞可能単語を確認しました. これらの単語は一般性が高いため, その文書を特徴づける単語としては適切ではありません. ゆえに, 文書の特徴の把握が難しくなります. したがって, 形態素解析によって形態素単位で分かち書きする処理の過程において, 「サ変接続」と「副詞可能」な単語も除外することによって, 把握が比較的容易なトピックの抽出が行えます.
補足
本記事では各トピックにおける出現確率の高い6個の単語の中で, 確率が最も高い単語をトピックであるかのように扱いましたが, 正しくはこの単語6個すべてが1つのトピック(話題のクラスタ)であり, そして話題クラスタごとに関連した単語が6個抽出されている状態です.
実際のところ, この話題クラスタが”何のトピック”であるかの決定は, 本人の裁量で行うができます. したがって, 本記事では話題クラスタの中で出現確率が最も高い単語をトピックとしました.
この辺りの話については, アイスクリーム屋さんで統計学がわかる -回帰分析・因子分析編- が分かりやすいので, 一読することをすすめます.
参考文献
- 岩田具治. “トピックモデル“. 2015.
- Toby Segaran. “集合知プログラミング“. 2008.
トピックモデルの基本についてはトピックモデルの4章を参考にしました. 実装には集合知プログラミングの10章を参考にしました.
最後に, トピックモデルについてまとめたスライド集(ALBERT Official Blog -『トピックモデルによる統計的潜在意味解析』読書会を開催中です)を見つけたのでリンクしておきます.